STAT 20: Introduction to Probability and Statistics
Agenda
Concept Questions
Problem Set 15
Concept Questions
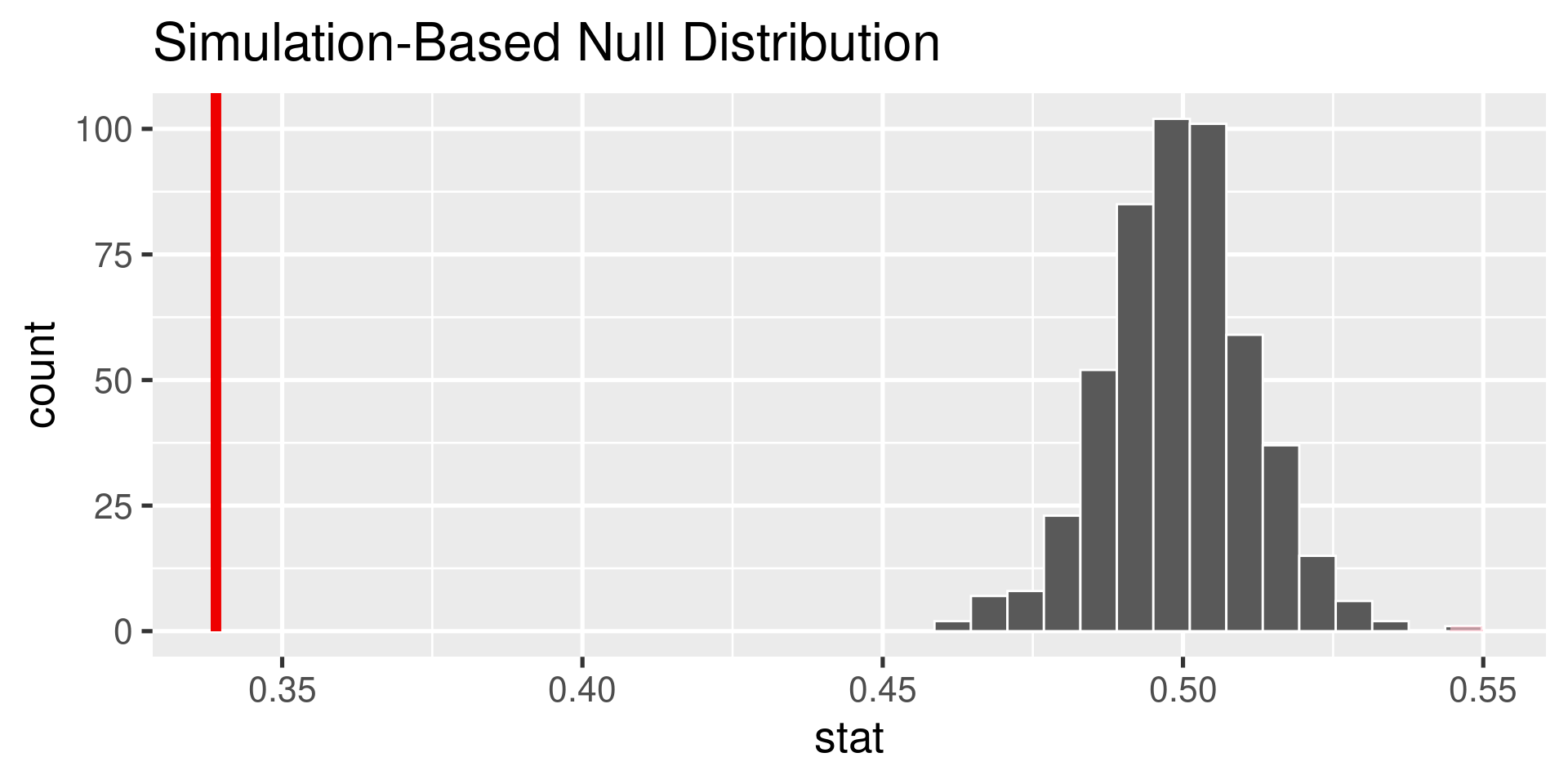
Instead of constructing a confidence interval to learn about the parameter, we could assert the value of a parameter and see whether it is consistent with the data using a hypothesis test. Say you are interested in testing whether there is a clear majority opinion of support or opposition to the project.