01:00
Hypothesis Tests II
Which pair of plots would have the greatest chi-squared distance between them? (consider one of them the “observed” and the other the “expected”)
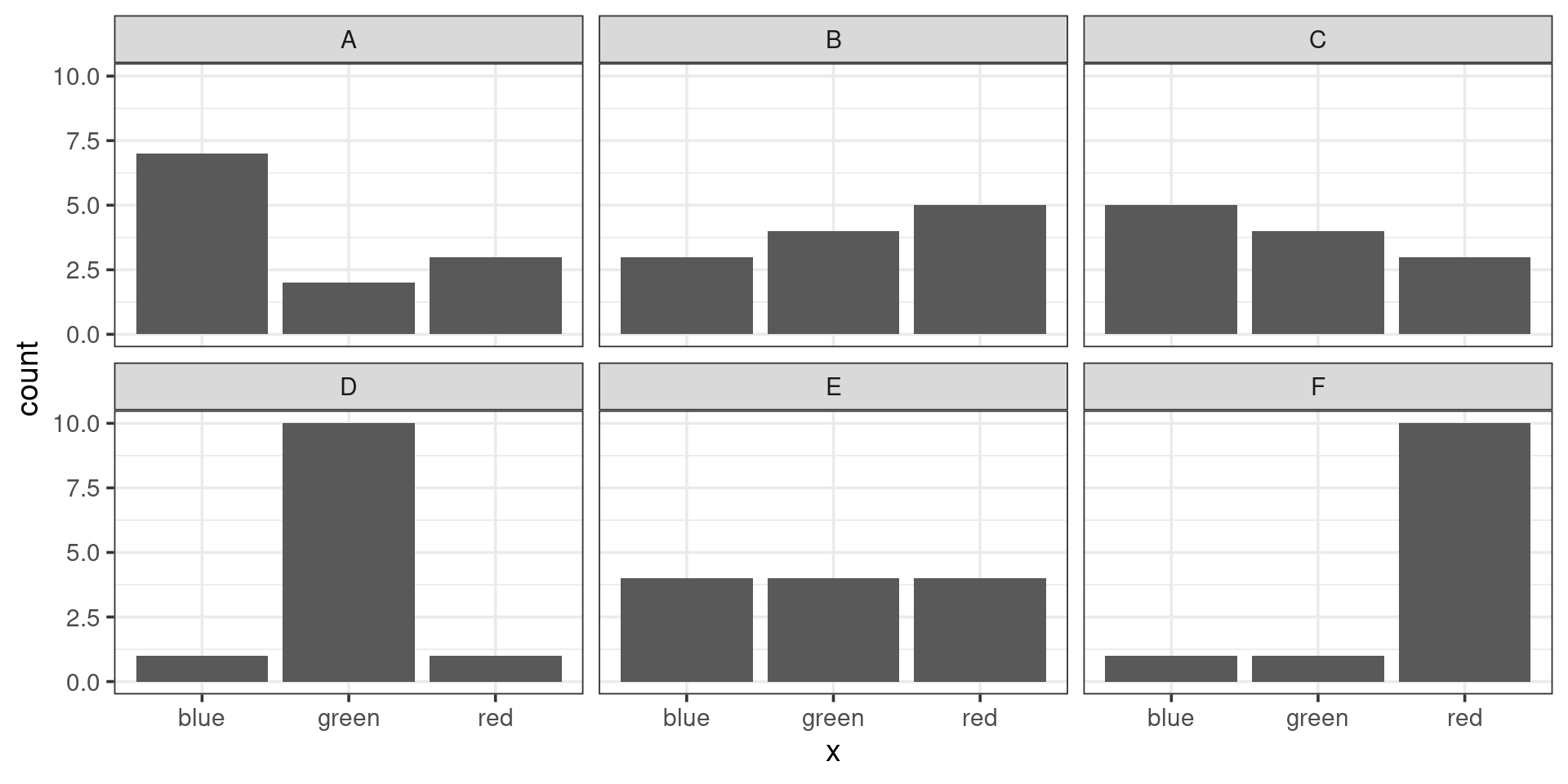
Chi-squareds Compared
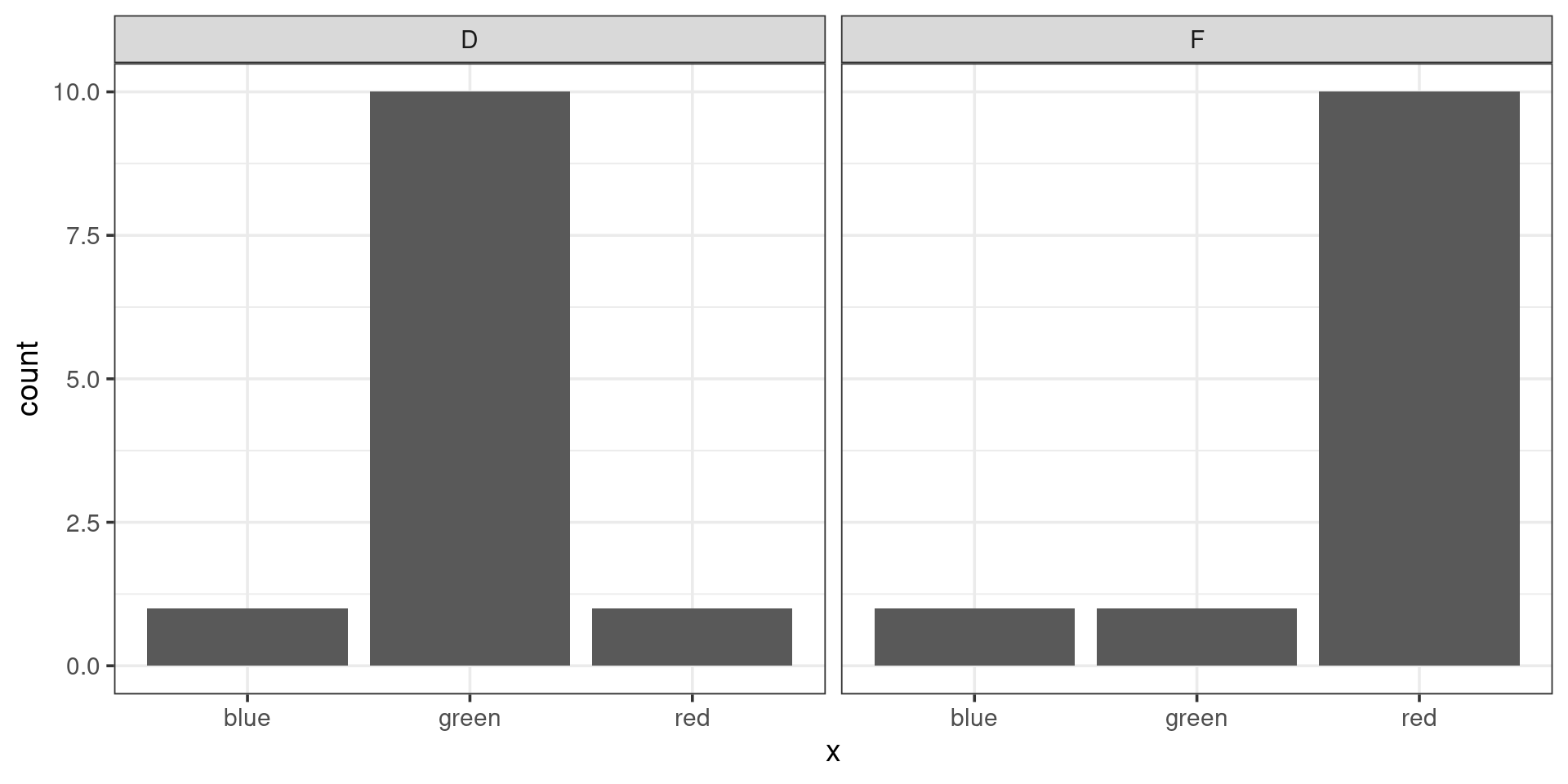
\[ \frac{(1-1)^2}{1} + \frac{(10 - 1)^2}{1} + \frac{(1 - 10)^2}{10} \\ 0 + 81 + \frac{81}{10} = 89.1 \]
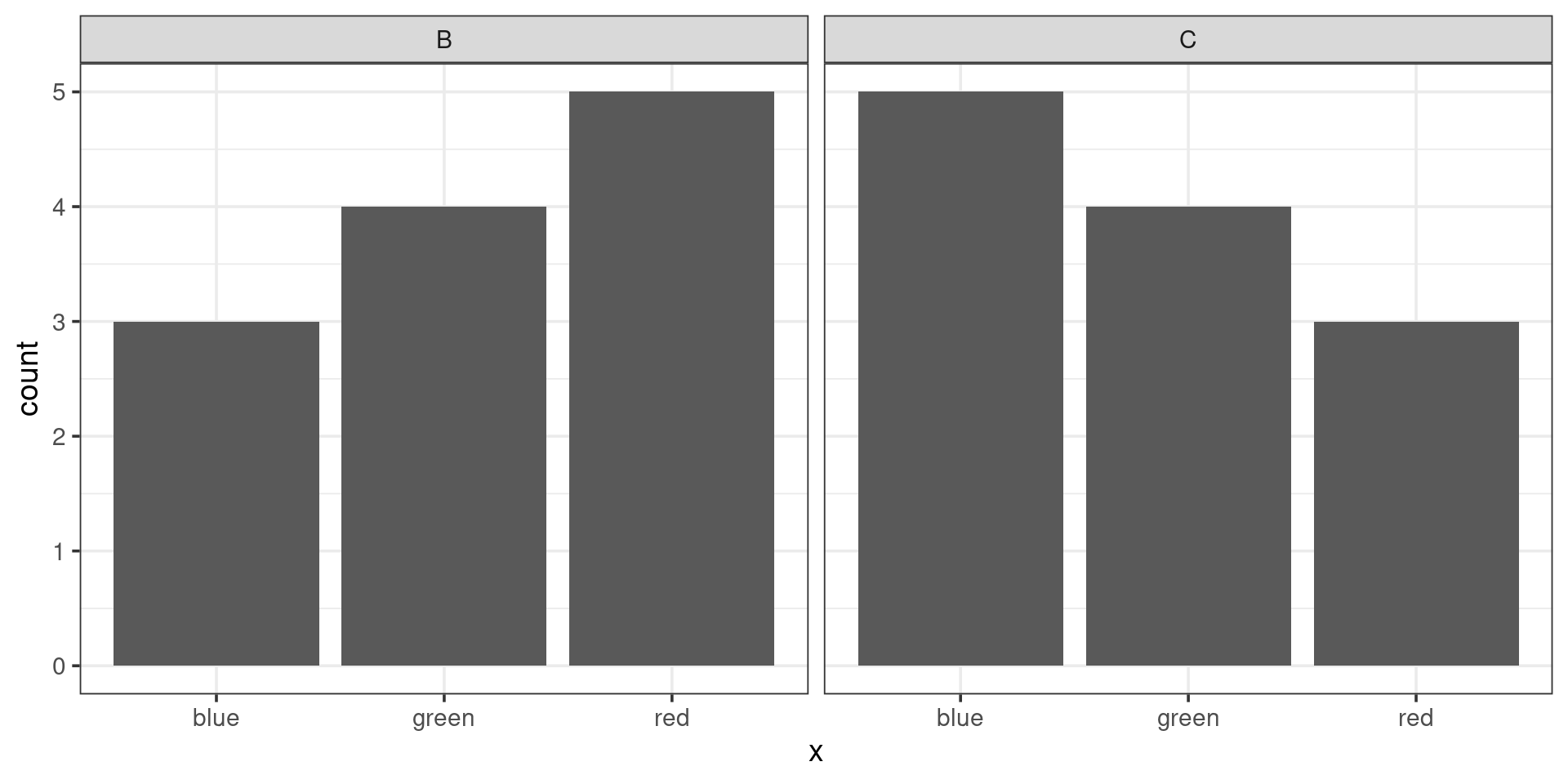
\[ \frac{(3-5)^2}{5} + \frac{(4-4)^2}{4} + \frac{(5-3)^2}{3} \\ \frac{4}{5} + 0 + \frac{4}{3} = 2.13 \]

The two shapes above have simple first names:
- Booba
- Kiki
Which of the two names belongs to the shape on the left?
00:15